2. What is High Performance Computing (HPC)?
Overview
Questions
- What is an HPC System?
- What are the components of an HPC System?
Objectives
- Understand the general HPC System architecture.
The words “cloud” and the phrase cluster or high-performance computing (HPC) are used a lot in different contexts and with various related meanings. So what do they mean? And more importantly, how do we use them in our work?
The cloud is a generic term commonly used to refer to computing resources that are a) provisioned to users on demand or as needed and b) represent real or virtual resources that may be located anywhere on Earth. For example, a large company with computing resources in Brazil and Japan may manage those resources as its own internal cloud and that same company may also use commercial cloud resources provided by Amazon or Google. Cloud resources may refer to machines performing relatively simple tasks such as serving websites, providing shared storage, providing web services (such as e-mail or social media platforms), as well as more traditional compute intensive tasks such as running a simulation.
The term HPC system, on the other hand, describes a stand-alone resource for computationally intensive workloads. They are typically comprised of a multitude of integrated processing and storage elements, designed to handle high volumes of data and/or large numbers of floating-point operations (FLOPS) with the highest possible performance. For example, all of the machines on the Top-500 list are HPC systems. To support these constraints, an HPC resource must exist in a specific, fixed location: networking cables can only stretch so far, and electrical and optical signals can travel only so fast.
What else is an HPC system good for?
While HPC is typically seen as where you go if you have large problems, HPC clusters can be used for even smaller cases where a single server is all that you need, or you have a reserach problem in which the task is very short, but you need to do tens of thousands of iterations, which is typically known as High Throughput Computing (HTC).
Components of an HPC System
Individual computers that compose a cluster are typically called nodes (although you will also hear people call them servers, computers and machines). On a cluster, there are different types of nodes for different types of tasks.
Anatomy of a Node
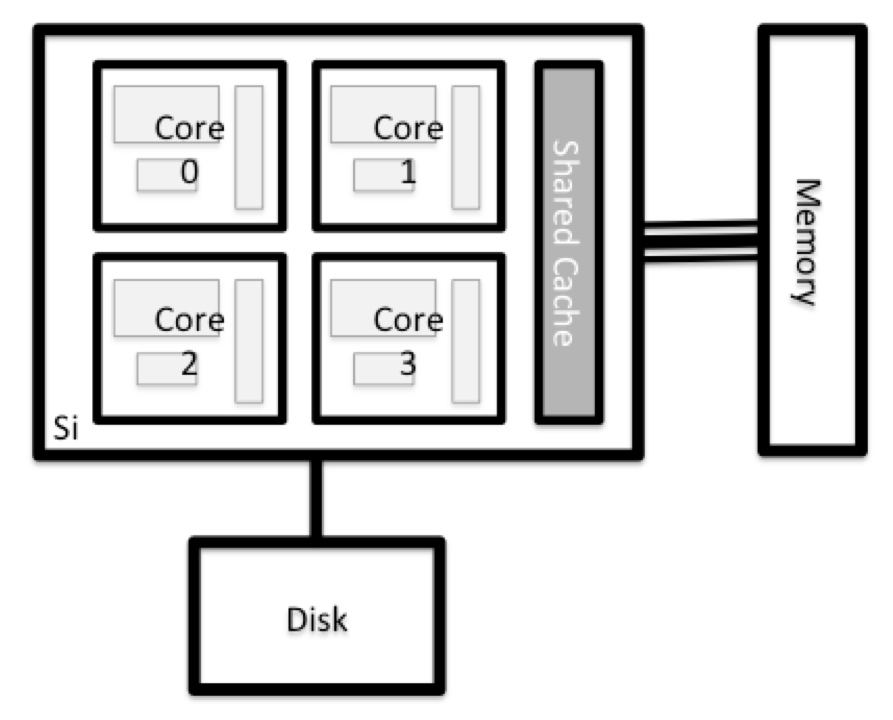
All of the nodes in an HPC system have the same components as your own laptop or desktop: CPUs (sometimes also called processors or cores), memory (or RAM), and disk space. CPUs are a computer’s tool for actually running programs and calculations. Information about a current task is stored in the computer’s memory. Disk refers to all storage that can be accessed like a file system. This is generally storage that can hold data permanently, i.e. data is still there even if the computer has been restarted. While this storage can be local (a hard drive installed inside of it), it is more common for nodes to connect to a shared, remote/network fileserver or cluster of servers.
Login Nodes
Serves as an access point to the cluster. As a gateway, it is suitable for uploading and downloading small files.
Data Transfer Nodes
If you want to transfer larger amounts of data to or from a cluster, some systems offer dedicated nodes for data transfers only. The motivation for this lies in the fact that larger data transfers should not obstruct operation of the login node. As a rule of thumb, consider all transfers of a volume larger than 500 MB to 1 GB as large. But these numbers change, e.g., depending on the network connection of yourself and of your cluster or other factors.
Data transfer nodes on Koa
Koa has four such data transfer nodes that are available for use with Globus.
Compute Nodes
The real work on a cluster gets done by the compute (or worker) nodes. Compute nodes come in many shapes and sizes, but generally are dedicated to long or hard tasks that require a lot of computational resources.
Differences Between Compute Nodes
Many HPC clusters have a variety of nodes optimized for particular workloads. Some nodes may have larger amount of memory, or specialized resources such as Graphical Processing Units (GPUs).
All interaction with the compute nodes is handled by a specialized piece of software called a scheduler.
Support nodes
There are also specialized machines used for managing disk storage, user authentication, and other infrastructure-related tasks. Although we do not typically logon to or interact with these machines directly, they enable a number of key features like ensuring our user account and files are available throughout the HPC system.
Key Points
- High Performance Computing (HPC) typically involves connecting to very large computing systems elsewhere in the world.
- These systems can be used to do work that would either be impossible or much slower on smaller systems.
For more information
This chapter used and modified material from the Introduction to High-Performance Computing Incubator workshop.